During the previous chapters, we learned how to interact with APIs to retrieve data. We also practiced retrieving the total number of objects that contain a specific term in a particular department of the Metropolitan Museum of Art.
In this chapter, we will take the next step: collecting and analyzing data using the Metropolitan Museum of Art API. Specifically, we will explore the question: What thematic areas can we identify from the terms associated with objects in the Medieval Art collection?
By analyzing how pairs of terms co-occur, we aim to uncover thematic areas and explore whether these topics reveal insights about Medieval Art — at least from the perspective of the Metropolitan Museum of Art’s metadata.
This chapter showcases how computational approaches can reveal hidden patterns in cultural data. By analyzing co-occurring terms in museum metadata, we aim to uncover thematic areas that define Medieval Art, helping us explore the implicit narratives within museum collections.
Preparing the data collection and preservation
Before starting to collect data, it’s important to think ahead and plan how the data will be collected, stored, and preserved for future use. Although this is a small project, we can follow some best practices to ensure data integrity and reproducibility.
Our first step is to create a directory structure to store the data and file naming conventions. We will create a directory called data to store both the raw and processed data. We will also create a directory to store the code used to collect data, and a directory to store the results of the analysis. Additionally, we will create a README.md file to document the project and a LICENSE file to specify the license under which the data is made available.
The project directory structure would look like this:
project/
├── data/
│ ├── raw/ # Original, unprocessed data
│ ├── processed/ # Cleaned and transformed data for analysis
├── code/ # Scripts used for data collection and processing
├── README.md # Project documentation
├── LICENSE # Licensing information
To ensure consistency, we will use clear and descriptive names for our files. For example:
raw_medieval_art_tags.csv: The original data collected from the API.
processed_term_pairs.csv: The processed dataset containing term pairs with weights.
Visit the project repository on GitHub to explore the full directory structure, example files, and scripts.
About Data Use
It’s important to check the data source documentation to identify the terms of use and any possible restrictions. In this case, the Metropolitan Museum of Art has published the data under a Creative Commons Zero (CC0) license. This means the data is free to use and distribute without restrictions. For more details, visit the API documentation.
What data to collect?
Before starting to collect data, we need to explore what data is available and how it can help answer our research question.
The first step is to examine a random object from the Medieval Art collection to identify useful fields for our analysis. We can use the endpoint https://collectionapi.metmuseum.org/public/collection/v1/objects?departmentIds=17 to retrieve a list of object IDs from the Medieval Art collection. Simply paste the full endpoint into your browser to see a response like this:
Once we have an object ID, we can use it to get detailed information about that object by appending the ID to the endpoint https://collectionapi.metmuseum.org/public/collection/v1/objects/{objectID}. For example, the object with ID 32830 gives the following detailed response:
{"objectID":32830,"isHighlight":false,"accessionNumber":"23.21.2","accessionYear":"1923","isPublicDomain":true,"primaryImage":"https://images.metmuseum.org/CRDImages/md/original/DP164978.jpg","primaryImageSmall":"https://images.metmuseum.org/CRDImages/md/web-large/DP164978.jpg","additionalImages":["https://images.metmuseum.org/CRDImages/md/original/DP164979.jpg"],"constituents":null,"department":"Medieval Art","objectName":"Manuscript cutting from a Dominican antiphonary","title":"Initial P with the Martyrdom of Saint Peter Martyr","culture":"Italian","period":"","dynasty":"","reign":"","portfolio":"","artistRole":"","artistPrefix":"","artistDisplayName":"","artistDisplayBio":"","artistSuffix":"","artistAlphaSort":"","artistNationality":"","artistBeginDate":"","artistEndDate":"","artistGender":"","artistWikidata_URL":"","artistULAN_URL":"","objectDate":"second half 13th century","objectBeginDate":1350,"objectEndDate":1400,"medium":"Tempera and ink on parchment","dimensions":"3 1/8 x 2 13/16 in. (7.9 x 7.1 cm)","measurements":null,"creditLine":"Gift of Bashford Dean, 1923","geographyType":"Made in","city":"Bologna","state":"","county":"","country":"Italy","region":"","subregion":"","locale":"","locus":"","excavation":"","river":"","classification":"Manuscripts and Illuminations","rightsAndReproduction":"","linkResource":"","metadataDate":"2024-10-03T04:53:53.567Z","repository":"Metropolitan Museum of Art, New York, NY","objectURL":"https://www.metmuseum.org/art/collection/search/32830","tags":[{"term":"Saint Peter","AAT_URL":"http://vocab.getty.edu/page/ia/901000056","Wikidata_URL":"https://www.wikidata.org/wiki/Q33923"},{"term":"Men","AAT_URL":"http://vocab.getty.edu/page/aat/300025928","Wikidata_URL":"https://www.wikidata.org/wiki/Q8441"}],"objectWikidata_URL":"","isTimelineWork":true,"GalleryNumber":""}
By exploring the object data, we can identify several fields of interest:
Field
Description
title
Name of the object
objectName
Type of object (e.g., Manuscript cutting)
medium
Materials used (e.g., Tempera on parchment)
culture
Cultural origin (e.g., Italian)
objectDate
Date or estimated time period
tags
Controlled vocabulary terms (AAT & Wikidata)
For our analysis, we will focus on the tags field, which provides a list of terms associated with the object. The tags field is particularly valuable because it uses controlled vocabularies like the Art and Architecture Thesaurus (AAT) and Wikidata, ensuring consistency across the dataset. These terms capture key themes and concepts, making them ideal for analyzing thematic areas in Medieval Art.
Documenting the focus of our analysis in a README.md file is a critical step in ensuring transparency and reproducibility. The README.md file provides future researchers (or your future self!) with a clear understanding of the dataset, its purpose, and how it was used. Here’s an example of how you can document this information:
Having identified the tags field as the focus of our analysis, we can include that information in our README.md file to document the project. This is an example of how we can include that information in the README.md file:
Medieval Art Collection Analysis
This project aims to analyze the Medieval Art collection of the Metropolitan Museum of Art. The focus of this analysis is on the tags field, which provides a list of terms associated with each object, using controlled vocabularies like the Art and Architecture Thesaurus (AAT) and Wikidata. With that information, we aim to identify thematic areas and explore whether these topics reveal insights about Medieval Art — at least from the perspective of the Metropolitan Museum of Art’s metadata, and propose a method to analyze arbitrary terms associated with museum collections.
License and right of use
The data provided by the Metropolitan Museum of Art is published under a Creative Commons Zero (CC0) license. This means that the data is in the public domain and can be used for any purpose without restriction. The derived data and code written for this project is published under the same license.
Collecting data
Now that we have identified the tags field as the focus of our analysis, we can start collecting data. To do this, we need to extract the specific information we need and store it in a format suitable for analysis.
Typically, this involves isolating the necessary information and storing it in a structured format like CSV (Comma-Separated Values). For our purpose, the CSV file will have two columns: objectID and tags. An example of the data is shown below:
This data was collected from the first 100 objects in the Medieval Art collection. It’s important to note that not all objects have tags, and some only have one term. Exploring the data is crucial to understanding its completeness and whether it can answer our research question.
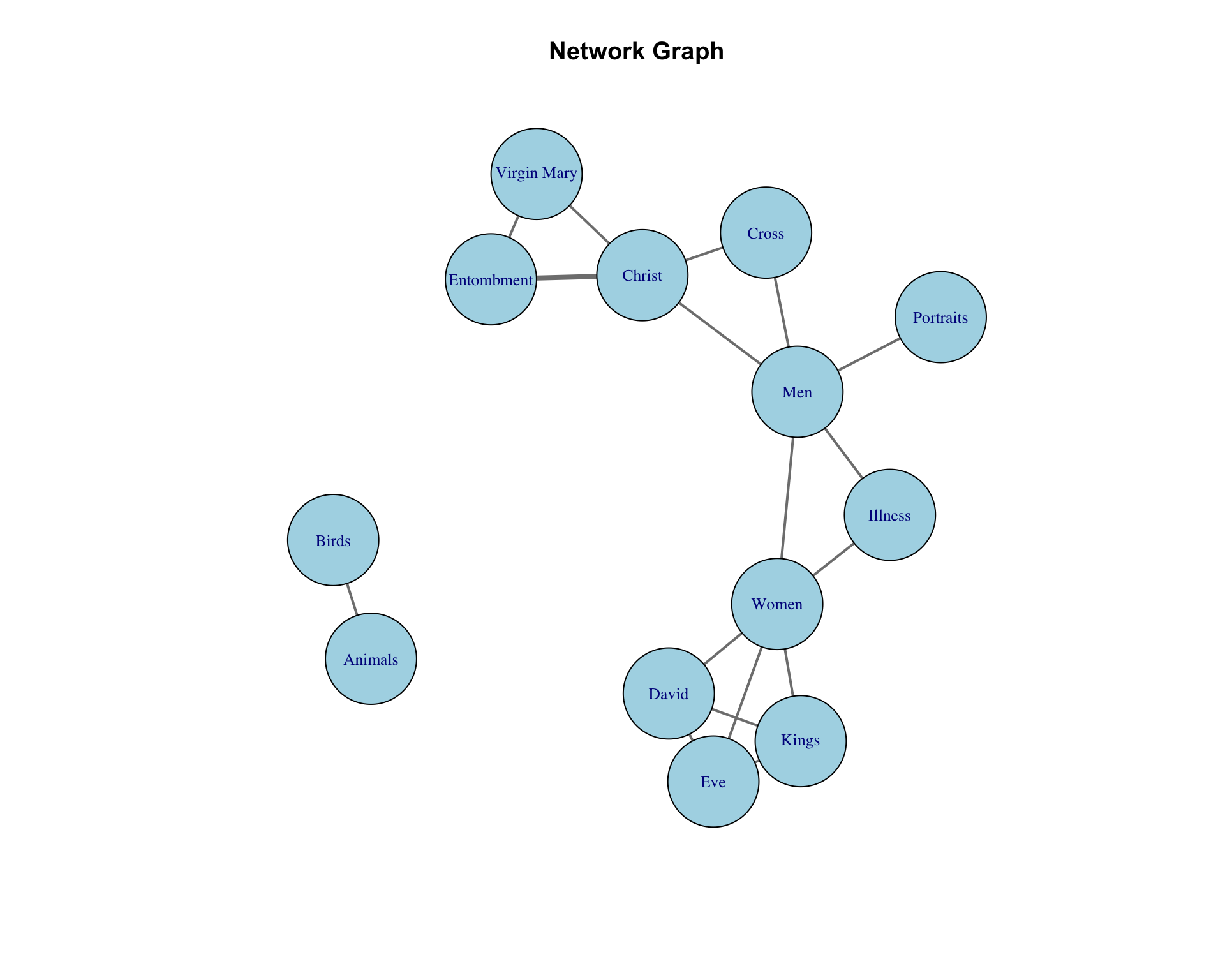
Instead of treating tags as separate labels, we analyze co-occurrence—when two terms appear together in the same object. By counting these relationships, we can visualize which themes are closely related across different artworks. Even with incomplete data, we can identify thematic areas. For example, we can extract term pairs that co-occur within the same object. For object ID 462990, the terms Entombment, Christ, and Virgin Mary co-occur, which can be represented like this:
Source,Target
Entombment,Christ
Entombment,Virgin Mary
Christ,Virgin Mary
When we notice that some pairs repeat across different objects, we can add weights to these pairs. For example, the pair Men and Cross appears in both 462992 and 462997, giving it a weight of 2. The table becomes:
This simple network graph provides a glimpse of the relationships between terms. For instance, we can see how the network is highly centered around the term “Men,” which connects with other groups associated with “Christ.” In contrast, “Women” is part of a smaller group tied to terms like “Eve,” “David,” and “Kings.” While this is just a small sample, it demonstrates how network analysis can reveal thematic patterns.
With this proof of concept, we’re ready to scale up to the entire Medieval Art collection. The complete data includes term pairs from 3695 objects, resulting in 1725 unique pairs. The dataset is stored in a CSV file, which can be accessed here: Medieval Art Data - Tags Pairs. Below is a preview of the first 20 rows:
Source Target Weight
1 Achilles Centaurs 1
2 Achilles Horses 1
3 Achilles Men 1
4 Achilles Tents 1
5 Achilles Trojan War 1
6 Adam Angels 1
7 Adam Christ 2
8 Adam Crucifixion 2
9 Adam Eve 6
10 Adam Nativity 1
11 Adam Virgin Mary 1
12 Adam Working 1
13 Adoration of the Magi Adoration of the Shepherds 2
14 Adoration of the Magi Angels 4
15 Adoration of the Magi Annunciation 5
16 Adoration of the Magi Beds 1
17 Adoration of the Magi Christ 8
18 Adoration of the Magi Crucifixion 6
19 Adoration of the Magi Dogs 1
20 Adoration of the Magi Jesus 6
Both raw and processed data are stored in the project repository. You can download the data directly from the repository to use it in your own analysis.
In the next chapter, we’ll use this full dataset to build a comprehensive network graph, analyze its structure, and uncover thematic clusters that provide deeper insights into the Medieval Art collection.
A Note About Automation
Manually collecting data from over 7,000+ objects would be time-consuming and error-prone. By automating the retrieval and processing of metadata, we ensure accuracy, reproducibility, and scalability—allowing us to apply this method to other museum collections in the future.
To collect the data for this project, we used a Python script to automate the process. The script performs the following steps:
Retrieves object IDs from the API.
Fetches tags for each object.
Generates term pairs and calculates weights.
Saves the results in a CSV file for analysis.
Code is available in the project repository. If you’re familiar with Python, you can experiment with it to collect data from other departments or customize it to fit your needs